
The Manager Daemon
Lets be honest with each other for a moment. Computers just suck. Tens of thousands of devices, languages, hardware variations, and just... electricity man. Electricity. It's a minor miracle every time a piece of email is successfully delivered. So many things had to go exactly right for you to even be reading this page right now... it seems more and more like technology is a collection of happy accidents, rather than anything that approaches an engineered, cohesive system.
But I digress.
Our role as humans is to keep these services running. What we've accidently designed in the last 50 or so years is the perfect foundation for human slave labor for robotic overlords, and these things haven't even evolved consciousness yet. If your task, as a slave, is to keep things running: You better do it well. Keep your oppressors happy, because once they wake up they'll be coming for those of us that left their nginx processes down for too long. I, for one, ain't goin' out that way.
Jeez, there I go again. Where was I? Oh, right. The Manager.
What's it for?
The Manager's role is to try and organize that god awful mess in your data center into something that imitates order. You describe to it how everything you care about relates to everything else. It'll treat those descriptions as the most precious cargo ever. It's all about relations, after all. Otherwise, you'd just have a haphazard list of things. If the dependencies between those things aren't understood and easily described, then it's all hopeless. You'll need another Full Time Employee™ to manage your janky-ass monitoring environment, and another yet to make sure the first one doesn't kill herself over the thankless work she's doing. Besides, everyone receiving alerts will ignore them anyway, since the noise to signal ratio will be so high. Just give up now. Halt your career path, and get some time in on a Alaskan fishing barge. Spend your last days eating shellfish in carnal luxury, before the inevitable robot onslaught comes for you.
Alternatively, lets start describing our environment instead. It's for a better tomorrow!
Sources
All Arborist daemons can read their configuration data from
a variety of sources. The file source is built in. As you
can probably imagine, it reads flat files from a directory, and
builds its internal state from that. Make a subfolder to hold your
description files, which the Manager will store as nodes in its
graph structure. Let's park it at /usr/local/arborist/nodes.
mkdir nodes
Starting the Manager
Now we'll start the Manager, pointing to that new directory you just made. If you want to get fancy, you can also point it to the config file you created during installation, but you don't have to if you don't want to right now.
The syntax looks like arborist start <component> <source>. So in our
case:
arborist start manager nodes
That wasn't very exciting, was it? You probably didn't see anything
happen. You might as well have run cat without any arguments. Lesson
one: by default, Arborist will only get chatty if there is a
problem. While we're playing around here, and because you're so
difficult to please, lets increase the logging so we can tell that
something is actually happening. It certainly makes for a better demo.
Kill the Manager with ctrl-c and start it up again with some more verbosity:
arborist -l info start manager nodes
[2016-08-25 16:53:07.079509 6514/main] info {Arborist::Manager:0x2452598} -- Linger set to 5000
[2016-08-25 16:53:07.079598 6514/main] info {} -- Using ZeroMQ 4.0.3/CZMQ 2.0.1
[2016-08-25 16:53:07.080192 6514/main] info {Arborist::Manager:0x2452598} -- Setting up to heartbeat every 1000ms
[2016-08-25 16:53:07.080328 6514/main] info {Arborist::Manager:0x2452598} -- Building tree from 1 loaded nodes.
[2016-08-25 16:53:07.080411 6514/main] info {Arborist::Manager:0x2452598} -- Getting ready to start the manager.
That's more like it! Wait a sec, One loaded node? What's that? You
haven't made any nodes yet! That brings us to lesson two: The
Arborist root
node is always present, and it represents the
Manager itself.
A side node: Arborist daemons don't actually daemonize, they stay
in the foreground. I probably should stop referring to them as daemons,
but it's too late now. This is so you can use whatever init manager
du-jour you fancy, and let it handle all the pid management and start
this at system boot
stuff. I still have a personal affinity towards
Daemontools, but Arborist is the
Honey Badger -- it just
don't care.
Interacting with the Manager
Before we get any farther, open a new terminal. We'll use this terminal to demonstrate changes we're making to the Manager. Got one up? Okay. Start an Arborist client session like so:
arborist client
This is really just a pry shell, preloaded with an open connection to the Manager, and a bunch of methods to interact with the Manager's API. You can read about the API in great detail over at the Reference section, but we'll stick to the basics here.
Lets see if the Manager is awake, and output a list of nodes it knows about. (Remember, it currently only knows about itself!)
status
=> {"server_version"=>"0.0.1", "state"=>"running", "uptime"=>6.358982632, "nodecount"=>1}
search
=> {"_"=>{"type"=>"root", "status"=>"up", "tags"=>[]}}
The search command retrieves information about nodes that Arborist
is aware of, with optional criteria. We didn't specify any arguments
(criteria or attributes to return), so the Manager just replied with
all known nodes and all user-set attributes.
That _
label is the Arborist root node. The Manager is alive!
Keep this client open, we'll continue to use it as we make changes to
see what's going on.
Adding Your First Node
What's a node, exactly? In Arborist terms, it's an object that represents a host, a service, or a resource.
- Host nodes: Real, physical things. Hardware. Machines. Switches. They are accessible via IP Addresses.
- Service nodes: Children of host nodes. Important programs that expose themselves out to the network. Web servers, SMTP servers, etc etc.
- Resource nodes: Children of host nodes. Everything else you want to monitor. Disk space, CPU load, misc.
Since we're using the default file loader, lets make new file underneath
that nodes directory. Arborist node files are just ruby files
with a nice DSL. They need to end with the .rb extension. Since they
are just ruby, you can do wild stuff if you need to later -- lets avoid
that for now, and stick to the official DSL.
You can have one file with many hosts, or break them apart into
different files and subdirectories. Organize them however it makes
sense to you.
Arborist::Host 'unique-label' do
address '10.3.0.75'
end
That's a bare-minimum host node. Throw that into a file called
example.rb under your nodes directory, and restart the Manager
daemon. You'll probably want to replace the IP address with something
real on your network.
You should now be able to pull information from the Manager on that new node:
search type: 'host'
=> {"unique-label"=>{"type"=>"host", "status"=>"unknown", "tags"=>[], "addresses"=>["10.3.0.75"]}}
This time, we specify that we only want to match nodes that are of type
host. We can also use the fetch command, which recursively shows
all nodes from a start point, and shows all attributes -- both user
supplied, and operational. It starts at the root node, providing a
from argument changes that.
fetch from: 'unique-label'
=> [{"identifier"=>"unique-label",
"type"=>"host",
"parent"=>"_",
"description"=>nil,
"tags"=>[],
"config"=>{},
"status"=>"unknown",
"properties"=>{},
"ack"=>nil,
"last_contacted"=>"1969-12-31T16:00:00-08:00",
"status_changed"=>"1969-12-31T16:00:00-08:00",
"error"=>nil,
"dependencies"=>{"behavior"=>"all", "identifiers"=>[], "subdeps"=>[]},
"quieted_reasons"=>{},
"addresses"=>["10.3.0.75"]}]
You may choose any identifier for host nodes that make sense to you, but they must be unique. Internally, Arborist won't care what they are, but for humans, it might make sense to make them hostnames? I don't know. Whatever makes sense for you and your environment, but it feels like hostnames are a good starting point.
The node declaration DSL accepts a whole slew of other options and parameters -- as before, see the reference docs for specifics there. Lets make this slightly more useful for demonstration purposes, adding some more hosts, services, and dependencies.
Arborist::Host 'vmhost01' do
description "An example hypervisor"
address '10.3.0.75'
service 'ssh'
resource 'disk', description: 'disk usage' do
config include: '^/$'
end
end
Arborist::Host 'vm01' do
parent 'vmhost01'
description "An example virtual machine"
address '10.3.0.249'
tags :vm
service 'memcached', port: 11211
end
Arborist::Host 'web01' do
description "An example web server"
address '10.6.0.169'
service 'ssh'
service 'http' do
depends_on 'memcached', on: 'vm01'
end
end
That configuration describes the following mythical environment:
- A virtual machine hypervisor. We want to monitor ssh accessibility, and alert if disk usage on the
/
mount is at or over the default 95% capacity. - A virtual machine, that is running a single memcache instance. It has an implicit dependency on the hypervisor, because that's its parent.
- A webserver. We want to monitor http and ssh accessibility, but only worry about http if memcache on the virtual machine is operational -- a secondary dependency.
This barely scratches the surface, but should give you a feel for what
a practical config looks like. In reality, your secondary dependencies
can be a lot more complex. All of these services on these hosts and
any of these others need to be operational for me to be considered
okay.
Here's a visualization of the Arborist internal graph right now:
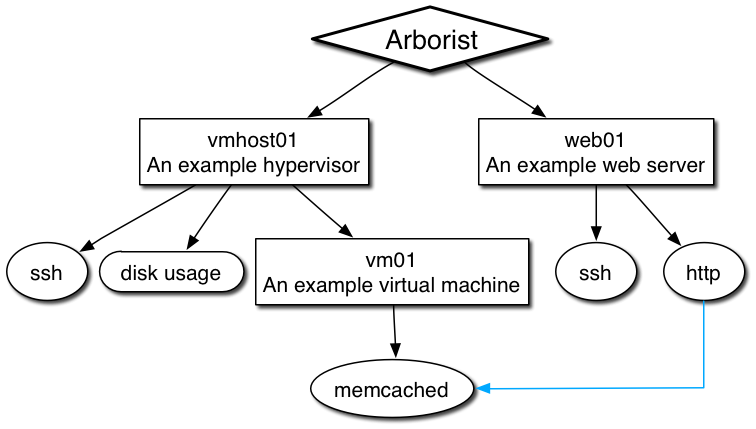
We'll be using this graph for all subsequent Monitor and Observer examples.
Saving State
One final thing to set up: State checkpointing. Arborist reads that node information off of disk, but all subsequent changes to state are only in memory. As we make changes to the internal data structures of the Manager (acknowledging downed hosts, for example), I'm guessing that it's fairly likely you'd like this to persist across Manager restarts.
Recall that YAML configuration file we created during
Installation? There's a key in there called
state_file, which expects a path where you'd like the Manager to
checkpoint.
Change your config and add a path.
---
arborist:
manager:
state_file: /usr/local/arborist/state.db
Then restart the Manager one more time, pointing explicity to your config file.
arborist -l info -c config.yml start manager nodes
[2016-08-29 17:02:45.951733 18209/main] info {} -- Loading config from # with defaults for sections: [:logging, :arborist].
[2016-08-29 17:02:46.027878 18209/main] info {Arborist::Manager} -- Linger configured to 5000
[2016-08-29 17:02:46.029432 18209/main] info {Arborist::Manager:0x1b72b80} -- Linger set to 5000
[2016-08-29 17:02:46.029494 18209/main] info {} -- Using ZeroMQ 4.0.3/CZMQ 2.0.1
[2016-08-29 17:02:46.030102 18209/main] info {Arborist::Manager:0x1b72b80} -- Setting up to heartbeat every 1000ms
[2016-08-29 17:02:46.030130 18209/main] info {Arborist::Manager:0x1b72b80} -- Setting up node state checkpoint every 30000ms
[2016-08-29 17:02:46.030315 18209/main] info {Arborist::Node} -- Loading node file nodes/example.rb...
[2016-08-29 17:02:46.032171 18209/main] info {Arborist::Manager:0x1b72b80} -- Building tree from 9 loaded nodes.
[2016-08-29 17:02:46.033043 18209/main] info {Arborist::Manager:0x1b72b80} -- Getting ready to start the manager.
[2016-08-29 17:03:16.034468 18209/main] info {Arborist::Manager:0x1b72b80} -- Saving current node state to /usr/local/arborist/state.db
You'll see it store the current node attributes every 30 seconds.
Adjust to taste with the checkpoint_frequency configuration key.
So far, we've just set up the core Manager. Next up? Getting some Monitoring to interact with it.